
DDD架构
...
更新于
491
次访问
DDD架构 终期目标:提供代码的可维护性,降低迭代开发成本。也是康威定律所述:任何组织在设计一套系统时,所交付的设计方案在结构上都与该组织的沟通结构保持一致。 参考文章 DDD 架构 | 小傅哥 bugstack 虫洞栈 架构分层 接口定义 - api:因为微服务中引用的 RPC(远程过程调用) 需
DDD架构
终期目标:提供代码的可维护性,降低迭代开发成本。也是康威定律所述:任何组织在设计一套系统时,所交付的设计方案在结构上都与该组织的沟通结构保持一致。
参考文章
架构分层
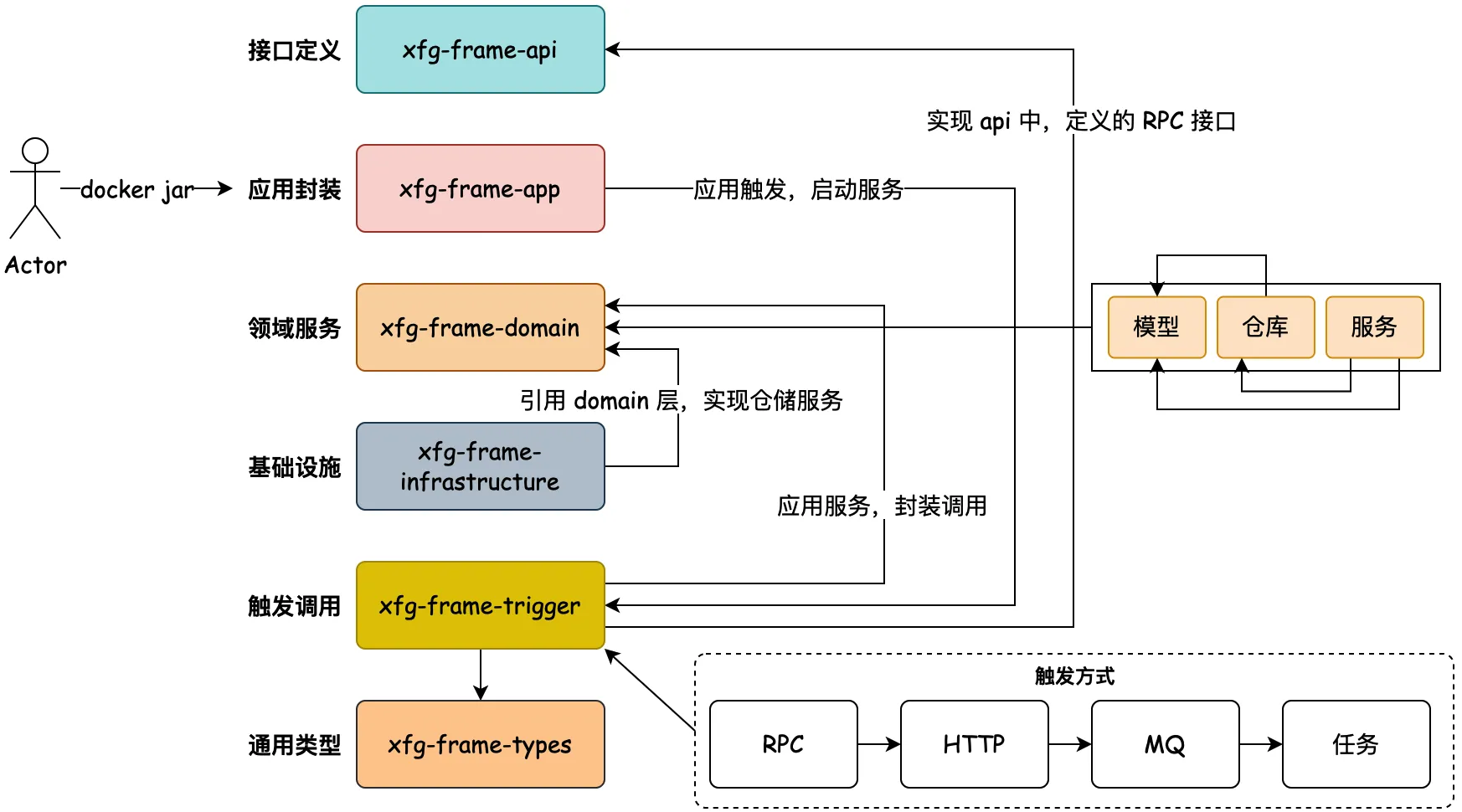
- 接口定义 - api:因为微服务中引用的 RPC(远程过程调用) 需要对外提供接口的描述信息,也就是调用方在使用的时候,需要引入 Jar 包,让调用方好能依赖接口的定义做代理。
- 应用封装 - app:这是应用启动和配置的一层,如一些 aop 切面或者 config 配置,以及打包镜像都是在这一层处理。你可以把它理解为专门为了启动服务而存在的。
- 领域封装 - domain:领域模型服务,是一个非常重要的模块。无论怎么做DDD的分层架构,domain 都是肯定存在的。在一层中会有一个个细分的领域服务,在每个服务包中会有【模型、仓库、服务】这样3部分。
- 仓储服务 - infrastructure:基础层依赖于 domain 领域层,因为在 domain 层定义了仓储接口需要在基础层实现。这是依赖倒置的一种设计方式。
- 领域封装 - trigger:触发器层,一般也被叫做 adapter 适配器层。用于提供接口实现、消息接收、任务执行等。
- 类型定义 - types:通用类型定义层,在我们的系统开发中,会有很多类型的定义,包括;基本的 Response、Constants 和枚举。它会被其他的层进行引用使用。
- 领域编排【可选】 - case:领域编排层,一般对于较大且复杂的的项目,为了更好的防腐和提供通用的服务,一般会添加 case/application 层,用于对 domain 领域的逻辑进行封装组合处理。
领域分层
DDD 领域驱动设计的中心,主要在于领域模型的设计,以领域所需驱动功能实现和数据建模。一个领域服务下面会有多个领域模型,每个领域模型都是一个充血结构。一个领域模型 = 一个充血结构
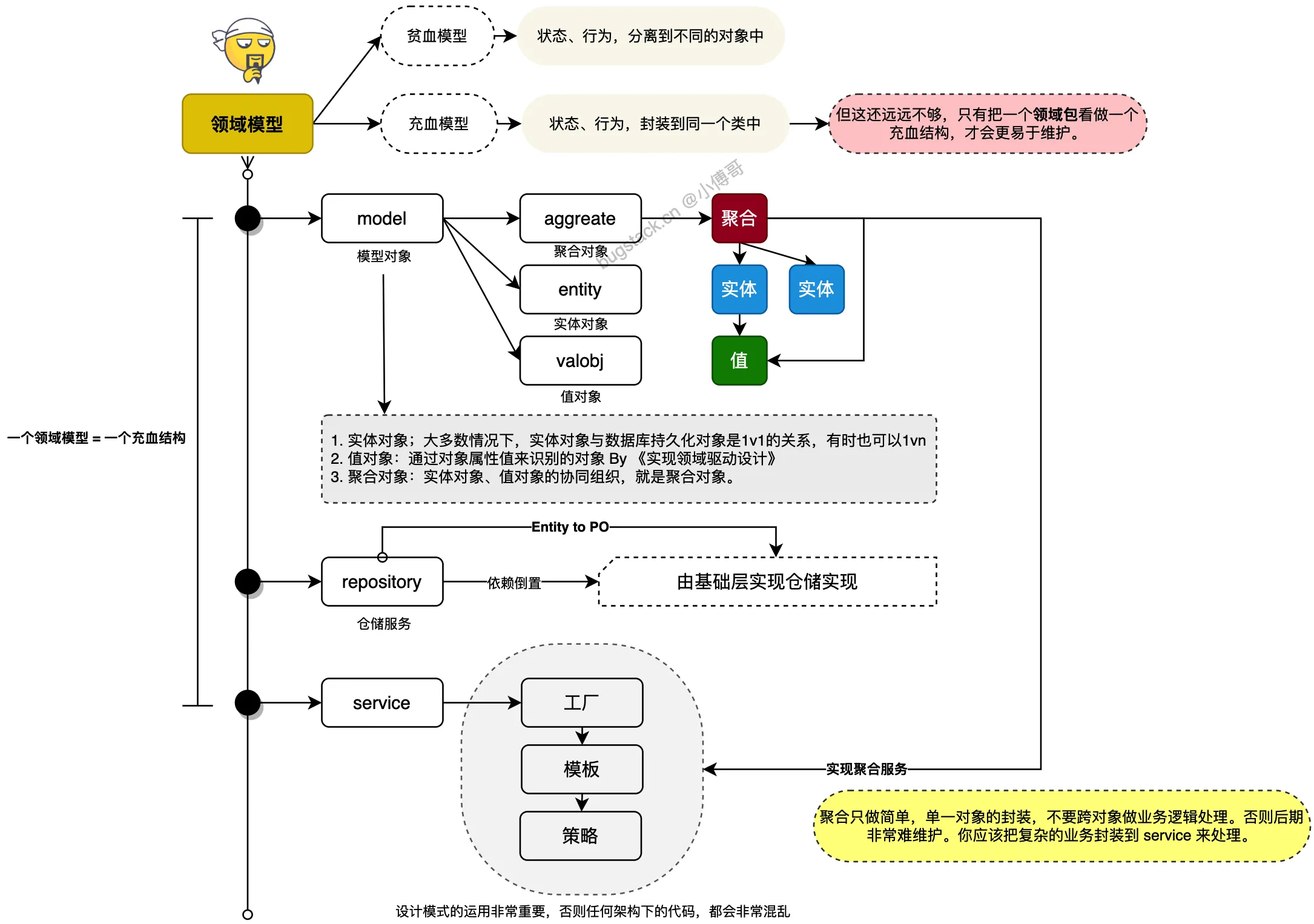
- model 模型对象;
- aggreate:聚合对象,实体对象、值对象的协同组织,就是聚合对象。
- entity:实体对象,大多数情况下,实体对象(Entity)与数据库持久化对象(PO)是1v1的关系,但也有为了封装一些属性信息,会出现1vn的关系。
- valobj:值对象,通过对象属性值来识别的对象 By 《实现领域驱动设计》
- repository 仓储服务;从数据库等数据源中获取数据,传递的对象可以是聚合对象、实体对象,返回的结果可以是;实体对象、值对象。因为仓储服务是由基础层(infrastructure) 引用领域层(domain),是一种依赖倒置的结构,但它可以天然的隔离PO数据库持久化对象被引用。
- service 服务设计;这里要注意,不要以为定义了聚合对象,就把超越1个对象以外的逻辑,都封装到聚合中,这会让你的代码后期越来越难维护。聚合更应该注重的是和本对象相关的单一简单封装场景,而把一些重核心业务方到 service 里实现。此外;如果你的设计模式应用不佳,那么无论是领域驱动设计、测试驱动设计还是换了三层和四层架构,你的工程质量依然会非常差。
- 对象解释
- DTO 数据传输对象 (data transfer object),DAO与业务对象或数据访问对象的区别是:DTO的数据的变异子与访问子(mutator和accessor)、语法分析(parser)、序列化(serializer)时不会有任何存储、获取、序列化和反序列化的异常。即DTO是简单对象,不含任何业务逻辑,但可包含序列化和反序列化以用于传输数据。
领域
一个领域模型中包含3个部分;model、repository、service 三部分;
- model 对象的定义 【含有;valobj = VO、entity、Aggregate】
- repository 仓储的定义【含有PO】
- service 服务实现
以上3个模块,一般也是大家在使用 DDD 时候最不容易理解的分层。比如 model 里还分为;valobj - 值对象、entity 实体对象、aggregates 聚合对象;
- 值对象:表示没有唯一标识的业务实体,例如商品的名称、描述、价格等。
- 实体对象:表示具有唯一标识的业务实体,例如订单、商品、用户等;
- 聚合对象:是一组相关的实体对象的根,用于保证实体对象之间的一致性和完整性;
关于model中各个对象的拆分,尤其是聚合的定义,会牵引着整个模型的设计。当然你可以在初期使用 DDD 的时候不用过分在意领域模型的设计,可以把整个 domain 下的一个个包当做充血模型结构,这样编写出来的代码也是非常适合维护的。
/